Single Image Depth Prediction Made Better:
A Multivariate Gaussian Take
|
CVL ETH Zürich1, UESTC China2, University of Würzburg3, KU Lueven4
|
|
The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
|
|
Abstract
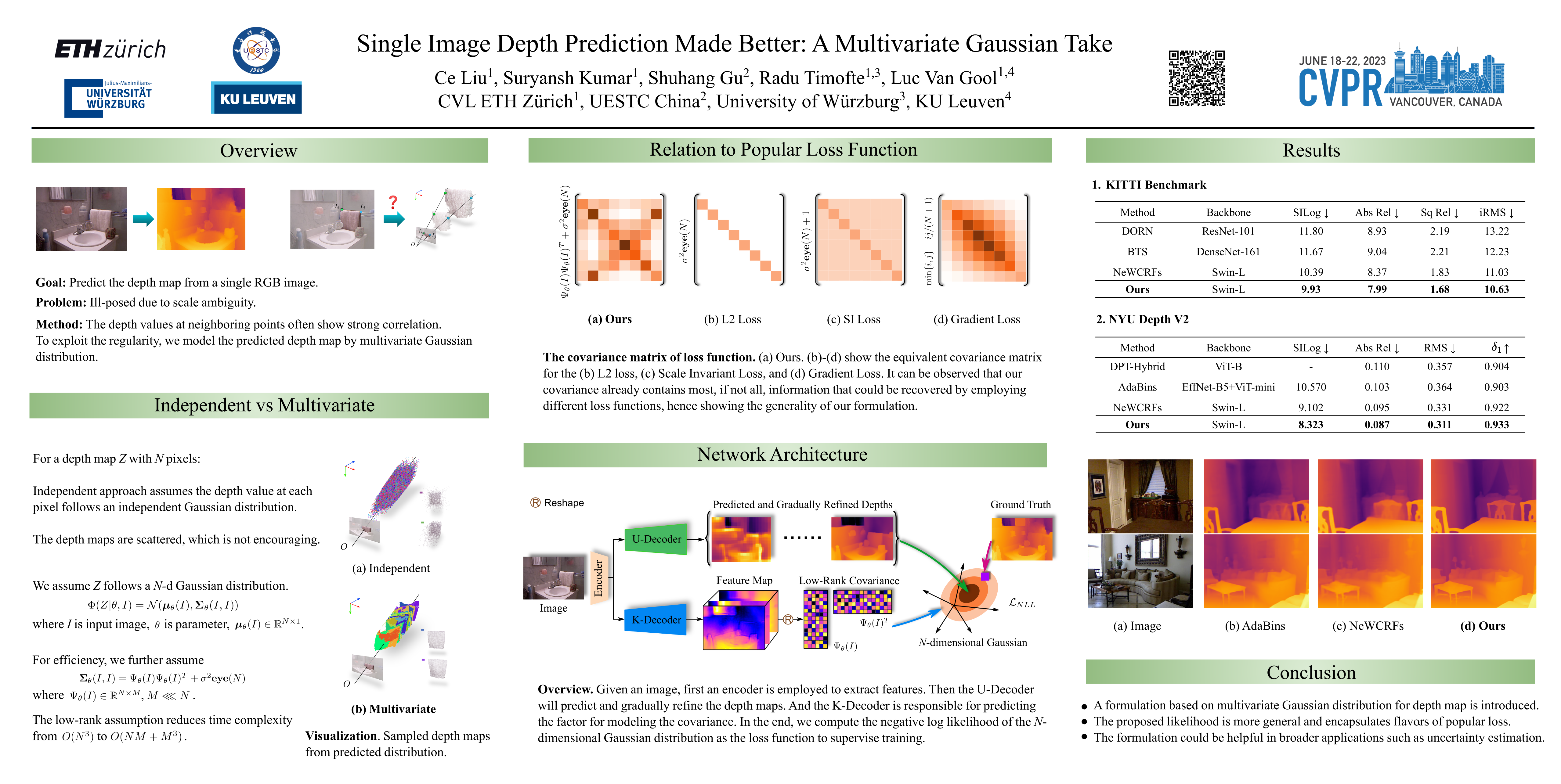
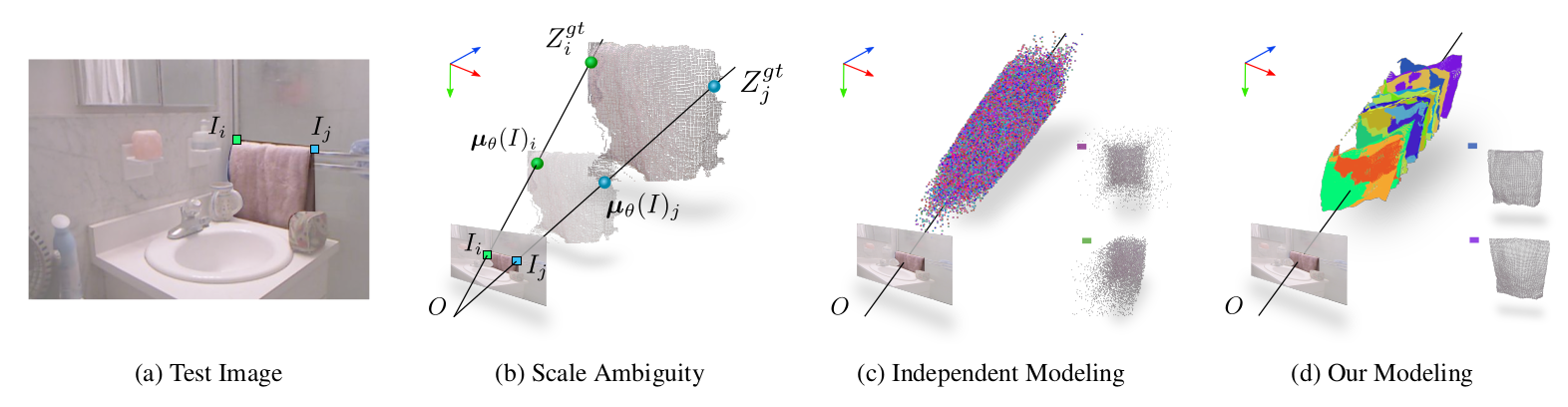
Neural-network-based single image depth prediction (SIDP) is a challenging task where the goal is to predict the scene's per-pixel depth at test time. Since the problem, by definition, is ill-posed, the fundamental goal is to come up with an approach that can reliably model the scene depth from a set of training examples. In the pursuit of perfect depth estimation, most existing state-of-the-art learning techniques predict a single scalar depth value per-pixel. Yet, it is well-known that the trained model has accuracy limits and can predict imprecise depth. Therefore, an SIDP approach must be mindful of the expected depth variations in the model's prediction at test time. Accordingly, we introduce an approach that performs continuous modeling of per-pixel depth, where we can predict and reason about the per-pixel depth and its distribution. To this end, we model per-pixel scene depth using a multivariate Gaussian distribution.
Moreover, contrary to the existing uncertainty modeling methods---in the same spirit, where per-pixel depth is assumed to be independent, we introduce per-pixel covariance modeling that encodes its depth dependency w.r.t. all the scene points. Unfortunately, per-pixel depth covariance modeling leads to a computationally expensive continuous loss function, which we solve efficiently using the learned low-rank approximation of the overall covariance matrix. Notably, when tested on benchmark datasets such as KITTI, NYU, and SUN-RGB-D, the SIDP model obtained by optimizing our loss function shows state-of-the-art results. Our method's accuracy (named MG) is among the top on the KITTI depth-prediction benchmark leaderboard.
Paper
 |
Single Image Depth Prediction Made Better: A Multivariate Gaussian Take
Ce Liu, Suryansh Kumar, Shuhang Gu, Radu Timofte, Luc Van Gool.
CVPR 2023, Vancouver, Canada.
|
Poster
Qualitative Results
The model is trained on NYU Depth V2, and evaluated on SUN RGB-D without fine-tuning.
Authors
 Ce Liu |
 Suryansh Kumar |
 Shuhang Gu |
 Radu Timofte |

Luc Van Gool |
Acknowledgements
|
This work was partly supported by ETH General Fund (OK), Chinese Scholarship Council (CSC), and The Alexander von Humboldt Foundation.
|